In our previous blog post series about privacy preservation, we introduced and analysed privacy risks with synthetic data from an engineering point of view. We illustrated the theory of various metrics for risk assessment. Now it is time for practice.
Clearbox AI’s solution makes it possible to generate high quality synthetic data, preserving the statistical properties of the dataset and reducing the risks of re-identifying individuals in the original data. Let’s generate a synthetic dataset and proceed with the risk assessment that we previously explained.
We are going to use the popular open dataset _UCI Adult_ that contains a set of categorical and numerical features about individuals. Here’s a short extract from the dataset:
We generated a synthetic dataset containing the same number of rows as the original dataset (about 32000), you can do the same through our Synthetic Data Platform (the free version may have data size restrictions). Together with the synthetic dataset, utility and privacy reports calculated by comparing the original dataset and the synthetic dataset are generated. Let‘s look at the contents of the privacy report to see how protected our dataset is from the possible re-identification risks of individuals in the original data.
We already know that with a good synthetic data generation, where new data records are generated from a distribution learnt by a (ML) model, and this is the case with Clearbox AI, there is no unique mapping between the synthetic records and the original ones. However, we should not underestimate related and nuanced risks. In some cases, for example, the generative model may overfit on the original data and produce synthetic instances too close to the real data. And even in the case of synthetic data that seems anonymous, sophisticated attacks could still lead to re-identification of individuals in the original dataset.
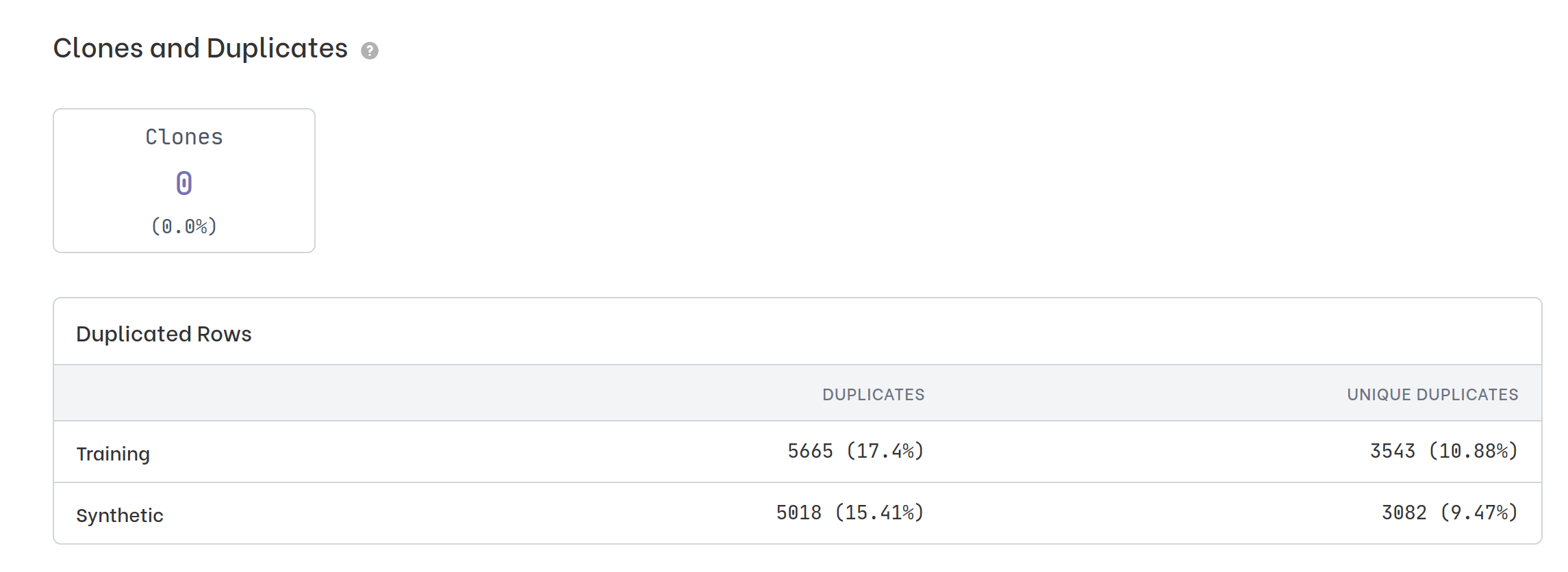
First, let’s check how many clones are present in the synthetic dataset. In other words, how many rows that were present in the original dataset are identical in the synthetic dataset?
In Figure 1, we are reassured that there are no clones within the synthetic dataset. The report also gives us information (the table in Figure 1) on the number of duplicates (identical rows) within the original dataset and in the synthetic dataset . This is complementary information to the number of clones that we need it to evaluate at least two things:
What if we have a large number of clones? It means that there are many synthetic instances matching at least one real individual, i.e. many real individuals are copied identically in the synthetic dataset. If that is the case, It is wise to stop and examine the situation better since the risk of re-identification could be high. The synthetic data generation process may need to be reconsidered, there may have been overfitting on the original dataset for example. However, this situation does not always indicate a high risk of re-identification: in some datasets the cardinality “covered” by the features might be so low as not to allow for a sufficiently diverse generation. Let me explain this better with an extreme example: if the original dataset has exactly 4 categorical features/columns and each has only two possible values there would be exactly 16 possible individuals, consequently any sufficiently large synthetic dataset will present identical instances to the original ones.
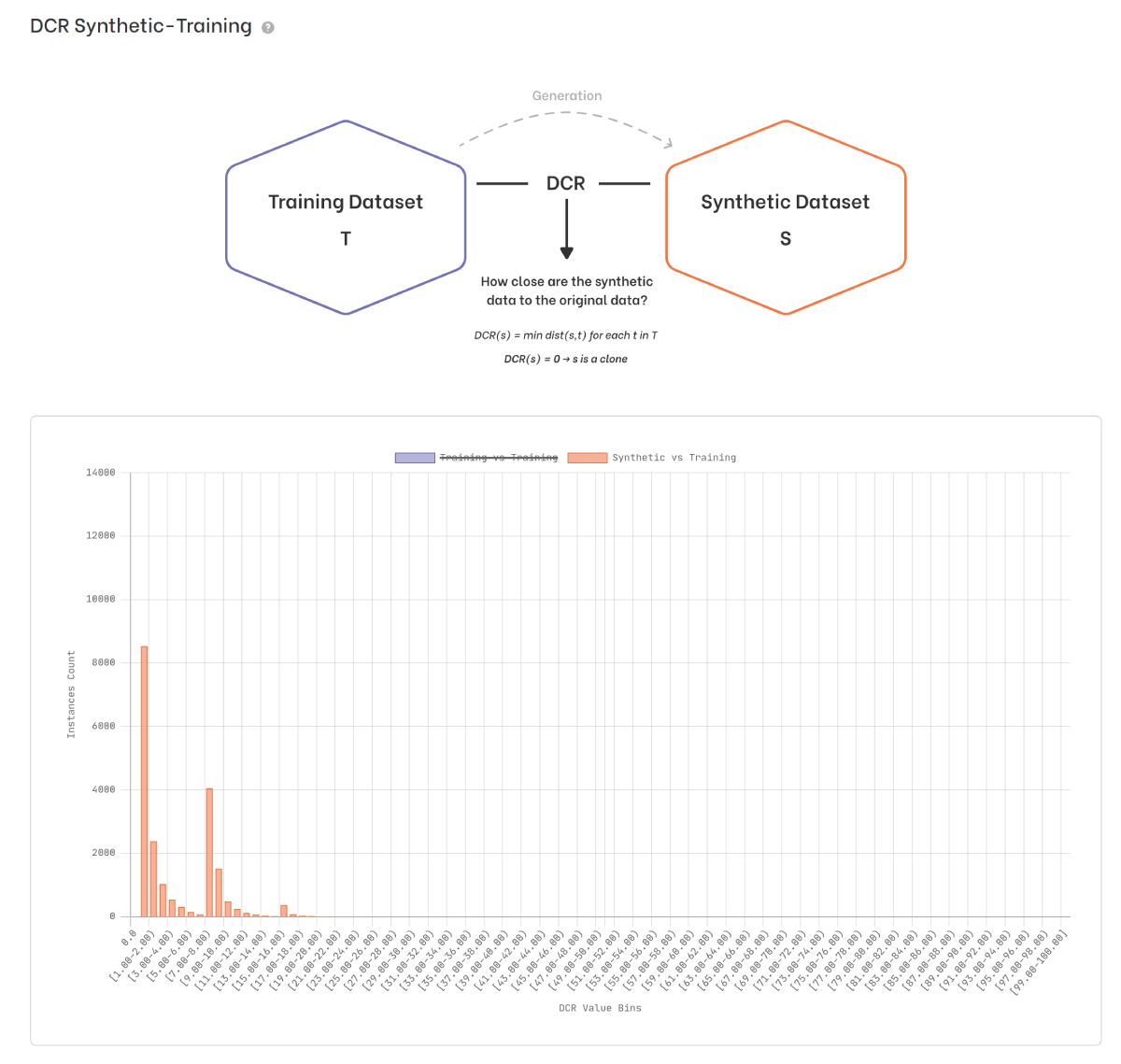
We proceed with the analysis by evaluating the DCR plot between the training dataset and the synthetic dataset:
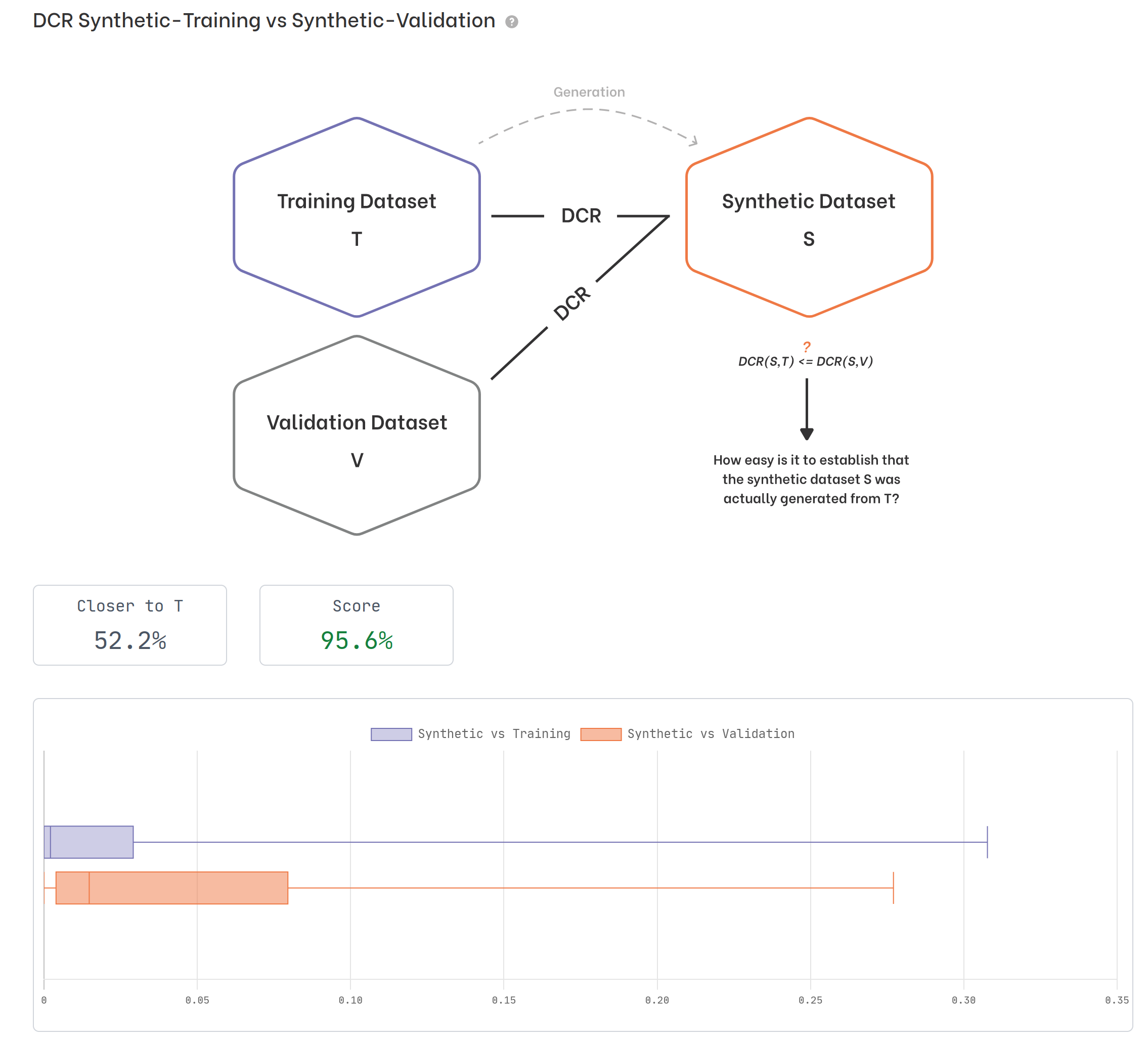
We note that, confirming the absence of clones, the first bar representing DCR=0 is completely absent. Furthermore, from the calculation of the DCR between the synthetic dataset and the validation dataset (below), we verify that synthetic individuals are not systematically closer to those in the training set than those in the validation set. It means that we were able to generate synthetic instances sufficiently different from the training ones and this results in a low risk of re-identification.
The distribution of distances between synthetic and training instances is very similar (or at least not systematically smaller) than the distribution of distances between synthetic and validation instances. We got a percentage close to 50%: this means that the synthetic dataset does not provide enough information that could lead an attacker to assume whether a certain individual was actually present in the training set.
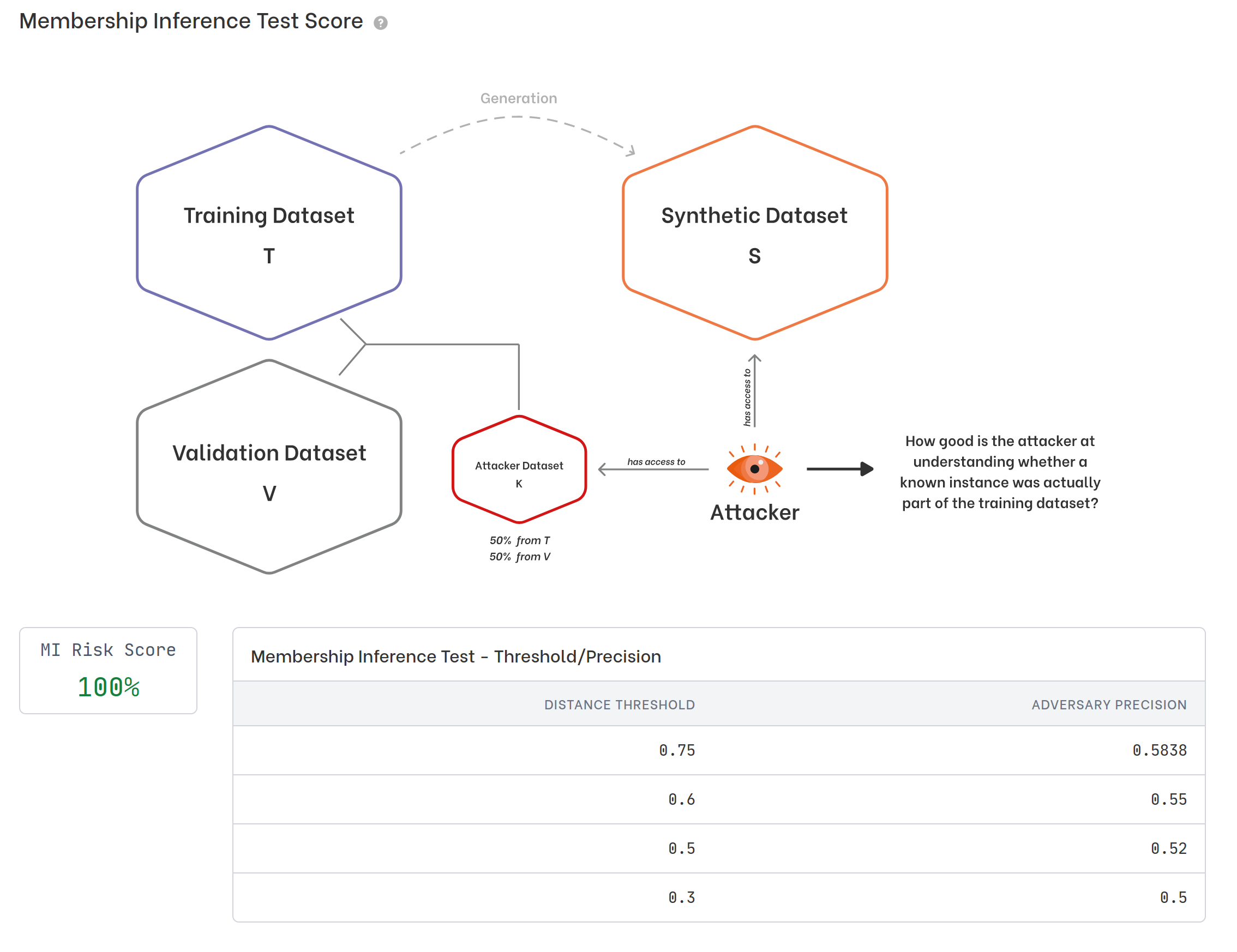
In the report we also get the risk assessment of a possible Membership Inference Attack:
We did very well in this case too: with different distance thresholds, gradually decreasing, the precision of the attacker is always around 0.5. A precision of 0.5 means that the attacker has made a random choice in determining whether or not a known instance (k) belongs to the training dataset. Despite the availability of the synthetic dataset S, he is not able to determine with a higher probability than random choice the membership of a known instance k in T.
In this post we saw how it’s possible to easily generate a synthetic dataset and evaluate its privacy profile. This blog post ends our series on synthetic data for privacy preservation. If you think this approach intrigued you to try it out or know more, please get in touch!