This is the third and last post of our series on the analysis of privacy risks with synthetic data from an engineering point of view. In the previous post, we introduced certain situations that presented these issues and that we need to take into account, and the first methodologies to quantify those risks. We are now going to define a specific risk, a Membership Inference Attack, and illustrate a method for calculating and protecting against it.
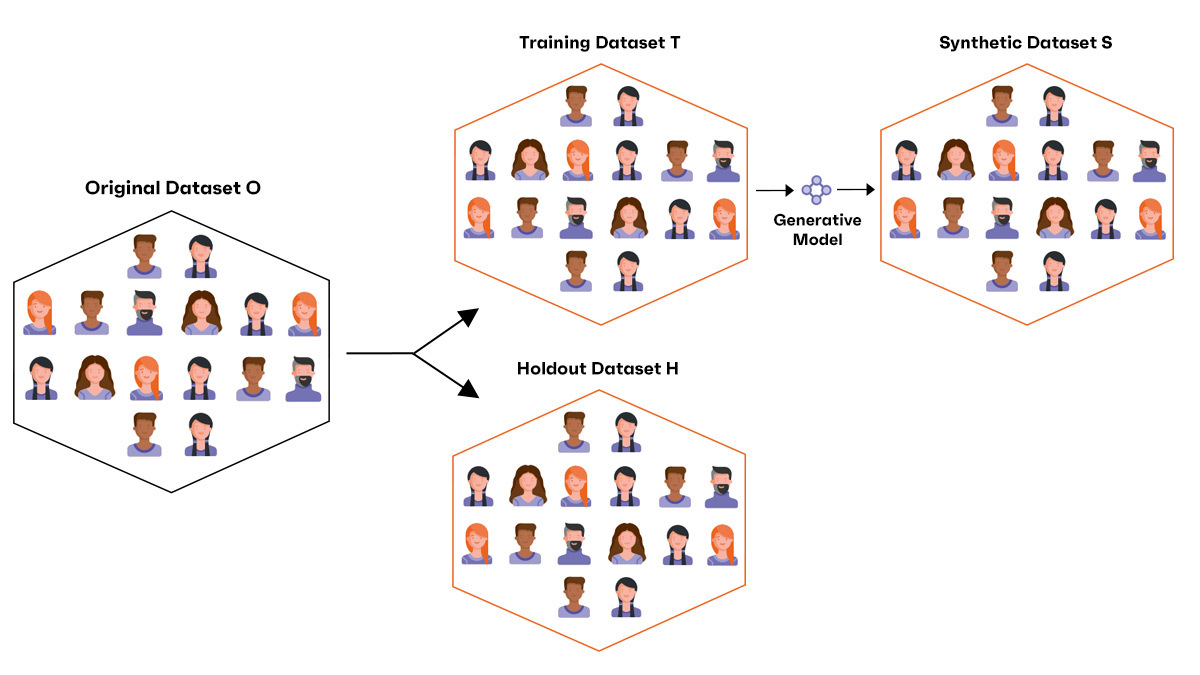
Let's go back to the scenario we previously defined: starting from an original dataset O we generate a synthetic dataset S with a certain degree of protection in terms of privacy. We want to prevent re-identification of any kind. We therefore want to stop a possible attacker A, having S at their disposal, from being able to derive sensitive information about real individuals in O.
We define a Membership Inference Attack as an attempt by a hypothetical attacker A to derive the membership of a specific individual in the original dataset O from which the synthetic dataset S was generated. In this case, it is not important that the attacker is able to identify the row in S that refers to a real individual, but only that he is able to verify that a specific individual was contained in the original dataset. This is a considerable risk that should not be underestimated. Let’s assume that the original dataset contains sensitive data on the customers of a bank. For instance, all customers with a large debt to the bank. If the attacker is able to deduce that a particular individual belongs to the original dataset, he may conclude that that person is a debtor of the bank. We must try to avoid this risk as much as possible.
Let us simulate this type of attack by assuming the scenario we had already illustrated in the previous post: we have split the original dataset in two sets: one part, the training set T, is used for synthetic generation while the second part, the holdout set H, is kept aside without being used by the generative model.
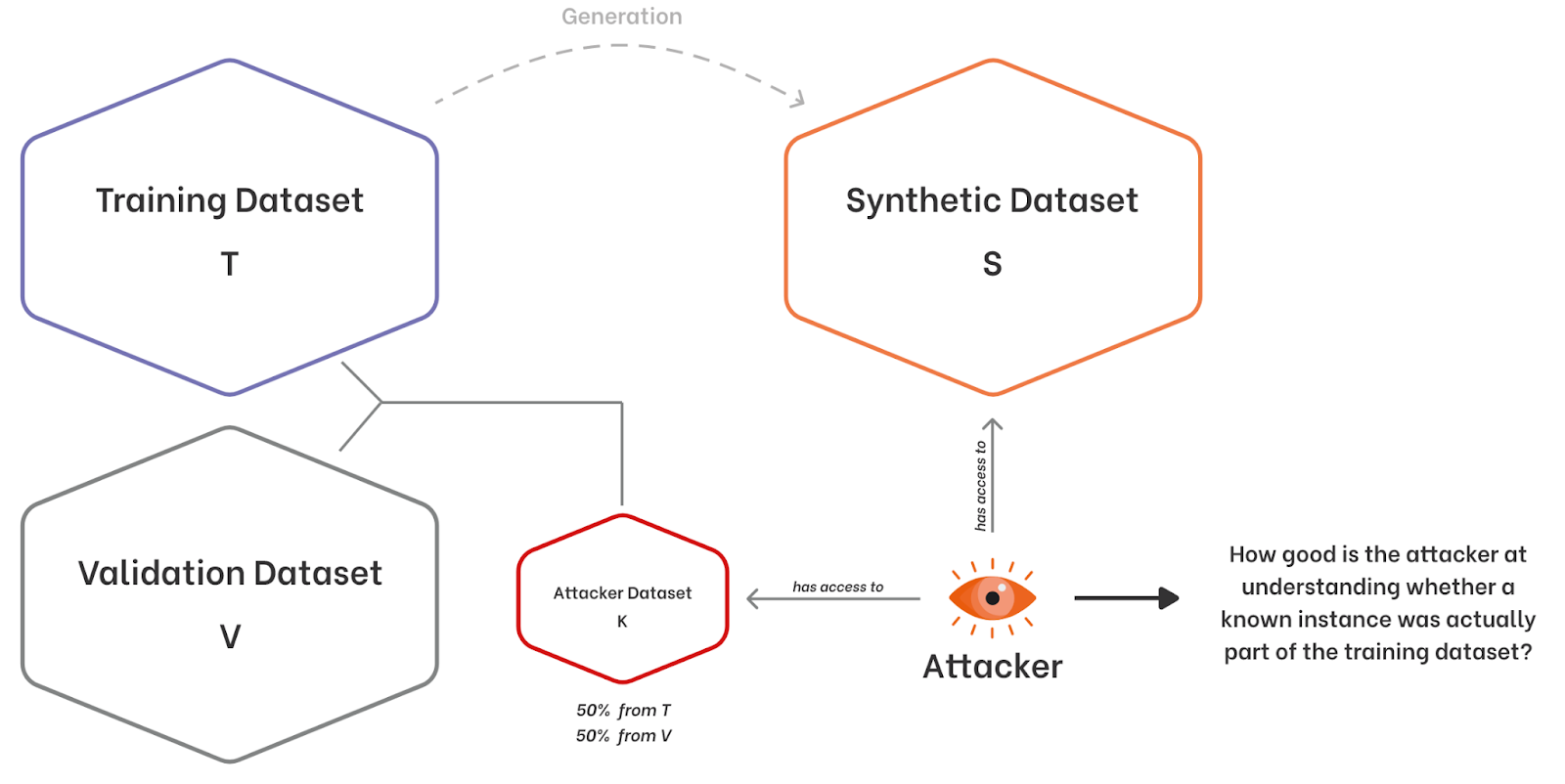
Let’s assume that attacker A has access to, in addition to the synthetic dataset S, an additional dataset K. This dataset K is a subset of the original dataset O, in particular half of its instances belong to the training dataset T and half belong to the holdout dataset H. Half of the instances in K were actually used for the generation of S, while the other half were not. It is not important to know how the attacker got hold of K, he may have obtained it through another attack or maybe the data in K are public.
The attacker has at his disposal a subset of individuals that may or may not belong to the training dataset on which the generative model for S was trained. The question we ask is: having K and S available, how difficult is it for attacker A to discover for each k in K whether k belongs to the training dataset T?
The attack consists of the following steps for each individual k in K:
1. The attacker identifies the individual s in S “closest” to k by means of the Distance to Closest Record (DCR) function we illustrated in the second post of this series; 2. The attacker establishes that k belongs to the training dataset T if the DCR value found in the previous step is below a certain fixed threshold.
Following this procedure, the adversary will have determined which and how many k individuals belong to the training dataset used for synthetic generation. To quantify this risk, let’s assess the success rate of this strategy.
Let ‘s keep in mind that in our scenario we know exactly for each k in K which was extracted from T (so it was used for the generation) and which from K (so it did not take part in the training of the generative model). For each k in K we can then know whether the adversary has correctly established its membership in T. We then have true positives, true negatives, false positives and false negatives. We can proceed to calculate the Precision of the attack strategy. In this case, the precision represents the percentage of correct decisions by the attacker.
Since 50% of the instances in K come from the training set and the other 50% come from the holdout set, we ideally aim for a precision of 0.5 or less. A precision of 0.5 means that the attacker has made a random choice in determining whether or not a known instance (k) belongs to the training dataset. Despite the availability of the synthetic dataset S, he is not able to determine with a higher probability than random choice the membership of a known instance k in T. As the value of precision increases, the attacker's ability to identify the membership of the training dataset increases and we will therefore have an increasing level of disclosure risk.
_This post ends the series about the analysis of privacy risks with synthetic data from an engineering point of view. We explained what it means to protect privacy with synthetic data and went into the details of some metrics useful to assess risks. You should not consider this an exhaustive list of all possible risks related to privacy preservation of synthetic data, but it should give a clear idea of the issue. Keep in mind that risk and remedy when it comes to data protection is based on the proportionality of the risk and impact. Synthetic data is a great contender as a safeguard mechanism in managing risks._