
Over the last few months, OpenAI's text-generating AI chatbot, ChatGPT, has emerged as a significant development in the AI landscape. The model, capable of crafting essays, code, and much more from brief text prompts, has been embraced by a wide range of users. Professionals in fields such as marketing, programming, and writing are using it to generate content, automate repetitive tasks, and aid in problem-solving. Meanwhile, everyday individuals are engaging with ChatGPT for everything from learning new topics, to drafting emails, to generating creative writing. ChatGPT's influence has expanded dramatically since its launch, and its capabilities have been further enhanced with the introduction of GPT-4, the latest language-writing model from OpenAI.
Given this rapid advancement and the growing versatility of ChatGPT, it's not surprising that some individuals and businesses might consider using it to generate synthetic data, including structured tabular data. After all, if a model can write a convincing news article or a compelling short story, why couldn't it also produce a detailed table of data? This idea, while intriguing, isn't quite as simple as it might seem.
It's indeed possible to use ChatGPT to generate a table of data with the right prompting and some constraints. Let's say, for instance, you need a table of fictional employees for a small company, including their names, roles, and years of experience. You could prompt the model like this:
Generate a table of 5 fictional employees for a tech company. Each employee should have a first name, last name, role, and years of experience. The roles should be different for each employee, and years of experience should range from 1 to 20. The table should be formatted as follows:
| First Name | Last Name | Role | Years of Experience |
|-----
The model will produce a response like this:
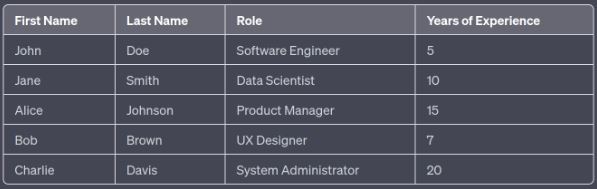
This is very cool. While this is a simple and relatively small table, we can also try to generate larger and more intricate datasets, even with relationships between columns. Let's take an example where we want to generate a fictional financial dataset for a small business, with the rule that the profit is always revenue minus expenses:
Generate a table of financial data for a fictional small business for the year 2023. Each entry should represent one month and include the month, revenue, expenses, and profit. The revenue and expenses should be random numbers between 10,000 and 100,000, and the profit should be calculated as revenue minus expenses. The table should be formatted as follows:
| Month | Revenue | Expenses | Profit |
|-------|---------|----------|--------|
The model will produce:
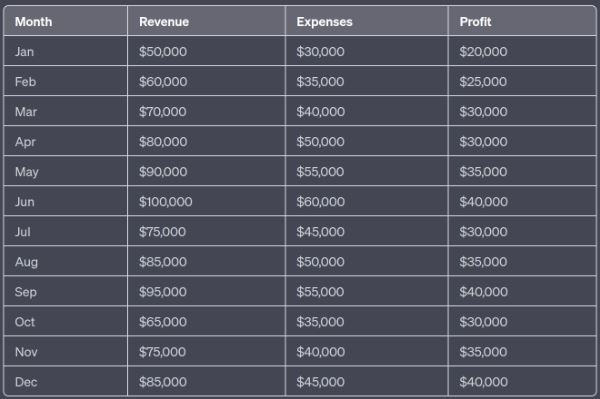
ChatGPT was able to implement the correlation rule defined in the prompt. It's quite astonishing. However, it's important to note that as the complexity and size of the desired data increase, so do the challenges and limitations of using ChatGPT in this manner.
Here's a complex prompt in the financial domain:
Generate a table of financial data for a fictional portfolio over a period of 12 months. The portfolio consists of three stocks: Stock A, Stock B, and Stock C. Each stock's price changes every month, following these rules:
- Stock A increases by 2% each month.
- Stock B decreases by 1% each month.
- Stock C increases by 1% in odd months and decreases by 1.5% in even months.
The portfolio starts with 100 units of each stock, and each stock starts at a price of $100. The table should include the month, the price of each stock, the total value of each stock in the portfolio (price times quantity), and the total value of the portfolio.
We tried this prompt on ChatGPT (based on GPT-3) and it was unable to consistently adhere to the rules. Some of the percentage increase and decrease calculations for the stocks were incorrect, leading to errors in the total values of the individual stocks and the overall portfolio. The tabulated data output by the model deviated from the expectations set by the prompt, thereby illustrating the difficulties GPT-3 encounters when handling such intricate tasks.
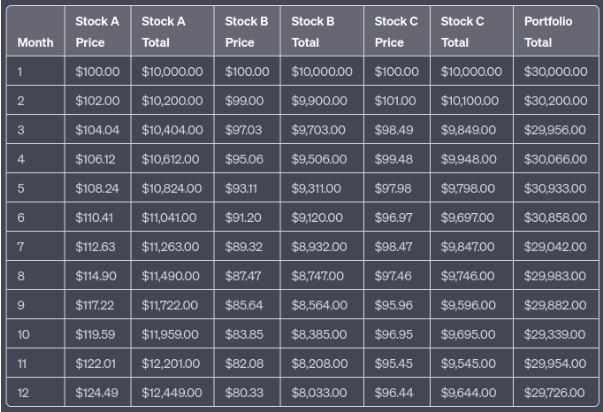
This experience reveals some important reasons why using language models, like ChatGPT, for generating complex synthetic tabular data might not be ideal. While these models have demonstrated exceptional capabilities in understanding and generating natural language, their efficacy in generating structured tabular data, particularly of a complex nature, is not as robust. Here are some key reasons:
- Mathematical and logical complexity: The intricate mathematical and logical calculations often required in structured data generation can be challenging for language models to get right. While they can perform basic arithmetic, more complex calculations and multi-step logical processes can pose difficulties.
- Representation of structured data: Language models are primarily designed for generating text, not structured data. They may struggle with maintaining consistent formatting, especially over larger data sets or more complex table structures.
- Maintaining correlation and dependencies: When generating synthetic data, it's often necessary to maintain certain correlations and dependencies between different data points or variables. This can be particularly challenging for language models, which are not inherently designed to understand or maintain such relationships.
- Performance and efficiency: For large datasets, generating synthetic data row by row using a language model is likely to be significantly less efficient than using dedicated data generation or simulation tools.
While the capabilities of language models like ChatGPT are indeed vast and impressive, their limitations in generating complex synthetic tabular data serve as a reminder that different tools are often better suited for different tasks. In the realm of synthetic data generation, other types of machine learning models and approaches often prove to be more effective.
Take for instance Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), two types of models that have been successfully employed in the generation of synthetic data. These models are designed to learn and mimic the distribution of a given dataset, thereby being able to generate new data that is statistically similar to the original. This makes them particularly adept at tasks such as generating synthetic tabular data, where maintaining the overall statistical properties and correlations within the data is crucial.
GANs and VAEs, thanks to their design, can handle the complexity and intricacy involved in generating structured synthetic data. They can maintain the necessary correlations and dependencies between different data points or variables, adhere to complex rules, and efficiently generate large volumes of data. Moreover, these models provide reproducibility, an essential feature when consistency and reliability of the generated data are paramount.
In essence, while language models have brought about a revolution in natural language processing and understanding, their use for generating structured synthetic data has clear limitations. As we move forward and continue to push the boundaries of what AI can achieve, it's vital to recognize the importance of using the right tool for the right task. For generating complex synthetic tabular data, models like GANs and VAEs often prove to be the more effective and reliable choice.
