From the very beginning, Clearbox AI has been dedicated to creating a product that is accessible and easy to integrate for our customers. Every company manages and stores data differently, and we knew that a flexible, retrofit, and straightforward solution would be crucial for you to benefit from the power of synthetic data generation through our product. As a result, we made it a priority to design Clearbox AI Enterprise Solution with comprehensive integration capabilities, allowing our customers to maintain their preferred data management procedures as well their data sovereignty.
A simple relational database may not be enough to handle organizations’ data management needs. This is where more advanced solutions like data warehouses come into play. Data warehouses are centralized repositories that store and manage large amounts of structured data. They play a vital role in the data management pipeline and are essential for businesses that need to make data-driven decisions. By using a data warehouse solution, organizations can handle their large amounts of data in an efficient and organized manner, allowing them to make informed decisions based on their data. Some popular private and public cloud based examples include Google BigQuery, Amazon Redshift, and Microsoft Azure Synapse. These solutions offer varying levels of scalability, performance, and cost-effectiveness.
We don't want to restrict the data warehousing and management choices of our Enterprise Solution users. We've put in a lot of work over the past months to find the ideal way to allow for a simple, comprehensive, and customizable integration with different data management pipelines. That's where Data Connectors shine. Data connectors are responsible for ingesting and injecting data within an organization's existing data infrastructure. They enable seamless integration with relational databases and data warehouses. Original data can be obtained from various sources easily and securely to be used in training our generative models. The resulting synthetic data can be saved with equal ease.
We provide out-of-the-box functions and support for most used relational databases (mySQL, PostgreSQL, Oracle, Microsoft SQL Server) and data warehouses (BigQuery, RedShift, Azure Synapse, Databricks). In addition, our Data Connectors are highly customizable and modularized. This means you can easily tailor the integrations to your specific needs and requirements.
Here is a brief example showcasing the connection to a dataset stored using Google BigQuery. The implementation logic for other data sources is quite similar.
Google BigQuery connector
Google BigQuery is a cloud-based data warehouse solution that leverages the power of Google's infrastructure to provide fast and efficient SQL queries. With its ability to store and analyze massive amounts of data using a familiar SQL-like syntax, BigQuery is a popular choice among organizations seeking to extract valuable insights from their data.
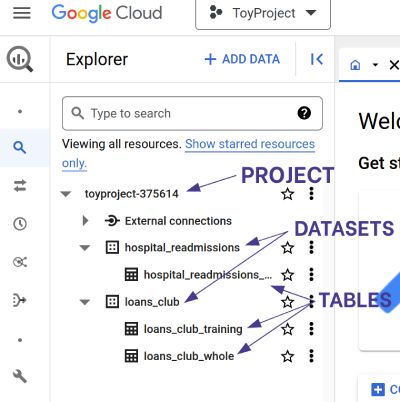
BigQuery storage has a hierarchical structure, consisting of projects, datasets, tables, and jobs. At the top level, projects act as a container for all the data you want to store. Each project can have one or multiple datasets, which in turn hold one or more tables. Tables store the data in a standard row-column format, while jobs are SQL queries used to access and manipulate the data.
Accessing a BigQuery Project via our Data Connectors requires a private credentials JSON key, which can be obtained by authenticating to the Google Cloud Platform API using a service account. Please refer to this guide for instructions and make sure to securely store the JSON key, as it is specific to a single project. If you need to access data from multiple projects, you will need a separate JSON key for each.
Once a successful connection has been established, it is possible to retrieve the list of datasets and tables within it, and then run specific queries whose results can be converted into the familiar pandas DataFrame format. At this point, the data is in the correct format to be used with the generative module of the Clearbox AI Enterprise Solution.
The reverse process is also possible with similar ease. The synthetic data produced by our solution and temporarily saved in a Pandas DataFrame can be loaded into a BigQuery table and made available to everyone within the organization.
This is how our Data Connectors work with Google BigQuery. We understand that every organization has unique data management needs, which is why our ever-expanding catalog of connectors includes Amazon Redshift, Microsoft Azure Synapse, Snowflake, and more. Our team is committed to continuously updating our connectors to ensure that our clients can seamlessly integrate with their preferred data management tools.
Our out-of-the-box support coupled with highly modularized and customizable connectors, ensure that our solution can be tailored to meet your specific needs and requirements with the ability to generate synthetic data in a way that is simple, efficient, and secure.