Recently, the Italian insurance company Generali asked for our help to overcome a specific challenge - sharing a database containing sensitive personal information across international divisions. Although the situation was pretty simple, the main obstacle with this use case was that the database contained dozens of relational tables.
The sensitive data belonged to a division without machine learning skills; they wanted to pass the database to a data science division to train a machine learning model for churn prediction. The client decided to use Clearbox AI's Enterprise Solution to generate a synthetic copy of the database and to pass it to their data analytics division to build the machine learning model. Before showing how the solution was used in this context, we will give a brief introduction about relational databases, highlighting their characteristics and the challenges associated with the synthetic generation.
What are relational databases?
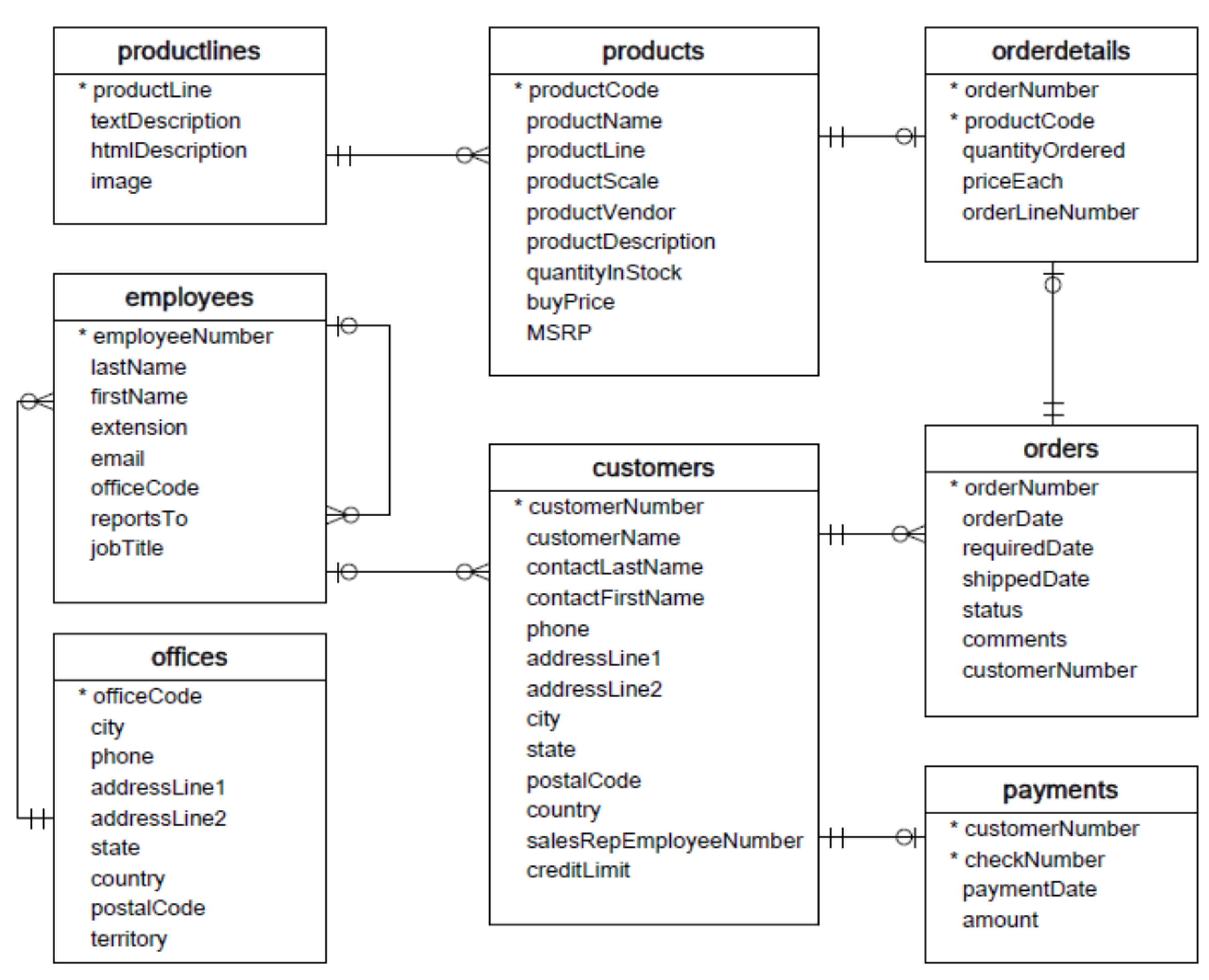
Relational databases are a type of database that store data in tables, with each table consisting of rows and columns. The rows represent individual records, and the columns represent the fields within those records. These databases are called "relational" because they are designed to store data in a way that allows for relationships between different tables and their records. In a relational database, relationships are established using keys. A primary key is a column or set of columns uniquely identifying a table row. A foreign key is a column or set of columns in one table that refers to the primary key of another table. See, for example, the figure below.
What are the challenges when generating synthetic relational tables?
When building machine learning models, performing several operations on relational databases is often necessary before training a model. These operations may include extracting data from the database, cleaning and preprocessing it, and then loading it into a format usable by the machine learning algorithm. Therefore, when generating synthetic tables, it is crucial that the relationships between tables are preserved. Not being able to do so will likely cause failures in the data pipelines once these are applied to real-life data. That's why we dedicated a lot of development effort to ensure that our product, the <strong>Enterprise Solution, is compatible</strong> with this type of data, producing realistic-looking relational tables.
How do we generate synthetic data based on relational tables?
Relationship discovery
The first step in generating synthetic relational data is extensive relationship discovery. Relationship discovery in multi-table relational databases refers to identifying the relationships between the tables in a database. Relational databases can contain dozens or even hundreds of tables, making it a tedious task to identify relationships between them manually. Identifying primary and foreign keys in each table is essential for understanding the relationships between tables, but it can be time-consuming.
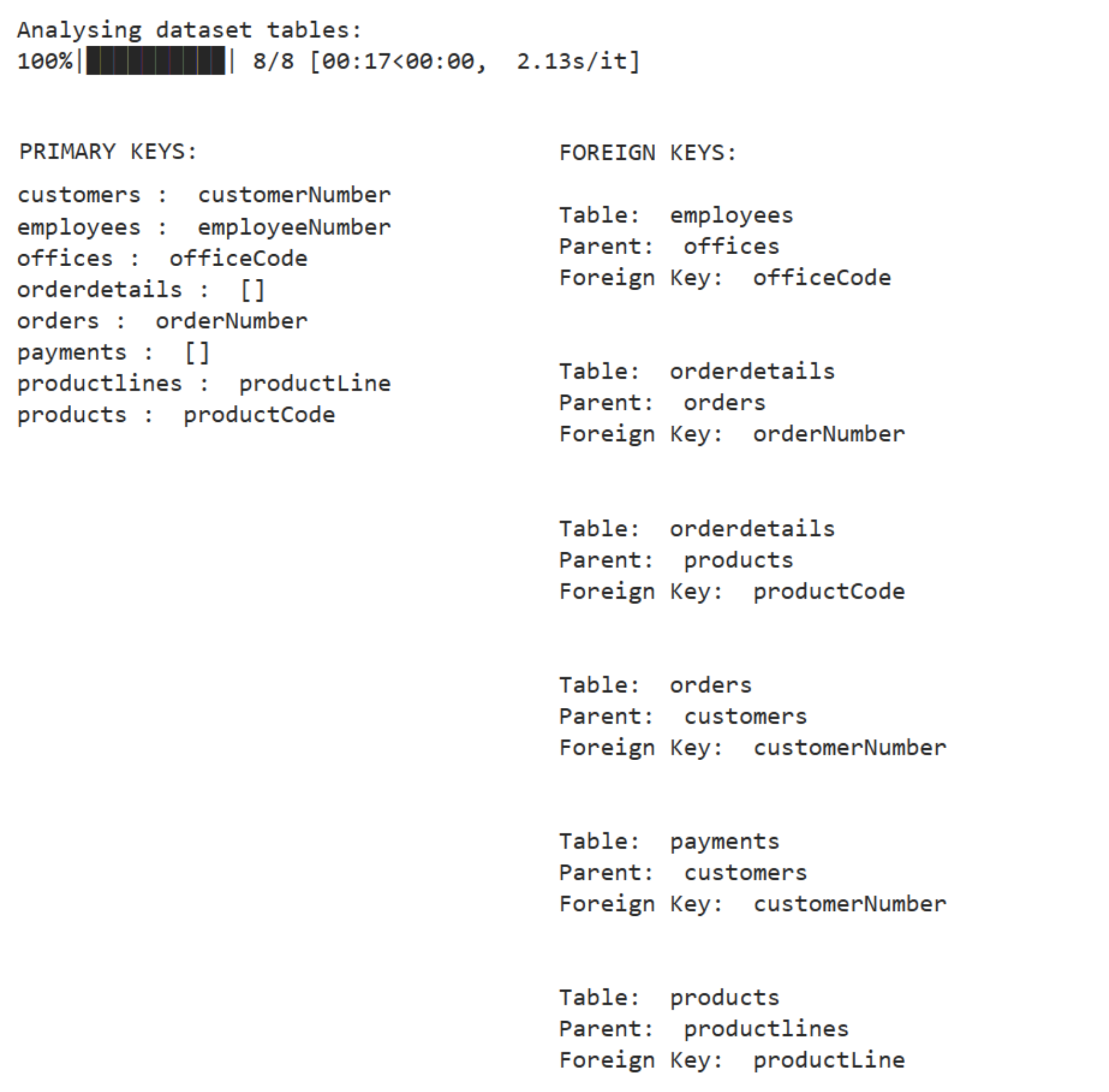
Our relationship discovery algorithms can automatically identify these keys and infer the relationships between tables. This module uses named entity recognition and data profiling algorithms to perform this step. The accuracy is, of course, not 100%, so we provide the user with the possibility of editing and correcting it. The output for the database shown in the figure above is, for example, the following output:
Users need to give the green light about the correctness of the relationship discovery step and eventually correct or include missing relationships.
Synthetic data generation
Once the relationships between tables in a relational database are defined, it is possible to generate synthetic tables using generative models. This can be done by training a conditional generative model to create new rows conditioned on a batch of rows from a foreign table.
A conditional generative model is a machine learning model trained to generate new data samples based on an input. In the case of relational databases, the conditions or input would be the rows from a foreign table that the model is conditioned on. This way, the model can learn the relationship between the two tables and generate synthetic data that preserves the same overall statistical properties and relationships as the original data while removing or altering sensitive information.
Measuring data quality
Evaluating the quality of synthetically generated tables corresponds to applying the same quality tests we use for single tables but to the joined ones. The evaluation report of a synthetic database consists of the reports for every single table and several reports associated with the tables obtained after the join operations defined during the relationship discovery.
When working with relational databases, it is essential to evaluate synthetic tables' quality when joined to make sure correlations between columns of different tables are preserved.
The same concepts apply to the analysis of the privacy properties of the synthetic database. In this case, the privacy score is an aggregate of the privacy score calculated for single and joined tables.
Conclusions
The database synthesized with our solutions contained dozens of different tables, and a manual setup would have been lengthy and tedious. The relationship discovery module of the Enterprise Solution allowed our client to save considerable time defining the data relationships information needed to have a high-quality synthetic copy.
The client used this synthetic database to extract a machine learning dataset to train a churn prediction model using their clients' sensitive data. The synthetic database generated with our solution contained the same predictive signal as the original dataset. Furthermore, preserving the relationships between tables ensured that data pipelines were robust even when exposed to real-life production data.
If you’re curious to know what else our Enterprise Solution can do for your company, read all about it here!