_This post is the first of a four-part series of didactic articles on uncertainty quantification in Machine Learning written by Dr. Luca Gilli. The current article introduces the readers to the basics of the topic with easy to follow examples. The subsequent articles will dwell deeper into the various methods, always with practical examples and use cases. This article series intends to provide practical guidance on advanced methods to data scientists and ML engineers to develop reliable ML models._
Machine learning models can achieve exceptional accuracy in solving many complex tasks. But it is important to remember they are not infallible and often make mistakes. A crucial indicator of trust in machine learning algorithms is undoubtedly the model confidence in a given prediction. Being able to anticipate the probability of a mistake gives the user the option (in certain situations) to discard a certain model recommendation.
The main reason machine learning models make mistakes is that they solve tasks by generalising from data that is associated with varying degrees of uncertainty. Therefore, it is pivotal to understand the different sources of uncertainty when designing a machine learning model.
I have recently found a very interesting paper on the topic of general uncertainty, where the authors do a great job of explaining the different types of uncertainty in supervised machine learning. There is a fundamental distinction that we have to make when dealing with uncertainty, i.e. the separation between the aleatoric and the epistemic types. The first type is the uncertainty associated with the randomness of a phenomenon (alea is a game of dice in latin), which is practically irreducible. It is impossible, for example, to predict the outcome of a dice throw, unless we consider the problem from a purely deterministic perspective. The second type is the uncertainty that is reduced by increasing the knowledge of the system that we are analysing. For example, we can reduce the uncertainty in the calculation of a bullet’s trajectory if we know the right value of its drag coefficient.
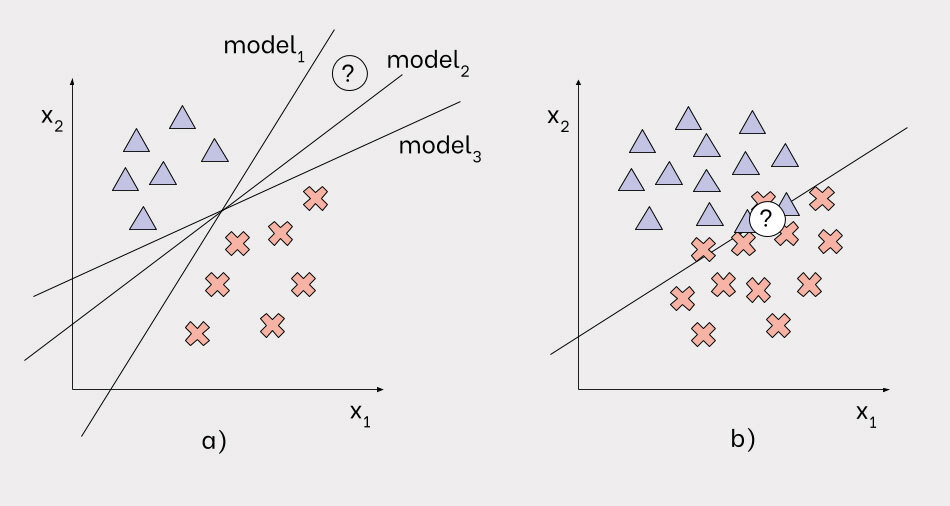
The same types of uncertainty exist in machine learning as well. Let me present to you a simplified example to demonstrate my claim. Let us assume we are dealing with a binary classification problem characterised by two features (x<sub>1</sub> and x<sub>2</sub>) and we want to train a linear model to differentiate two classes (triangles and crosses). The following figure shows two sets of training points drawn from the same distribution, however on the left side (a) we have fewer points than on the right side (b). Let us start from the situation depicted in (a) and assume we want to train our linear classifier on this set of points.
As the figure a) shows we have various possibilities to differentiate between the points, as you can see the lines representing models 1, 2, 3 are equally good at separating triangles from crosses. The reason is that we do not have enough data points in certain regions to determine the best model among the three. If any of these models was asked to give a prediction for the point represented by the question mark, such a prediction would be characterised by a fairly high uncertainty of the epistemic type. This means none of these models has enough experience in that region of the feature space. On the other hand, if we could determine the right answer for the point as a cross, we could discard model 2 and 3 from our hypothesis space, thereby reducing uncertainty.
The right side to the figure (b) shows a different situation. Here the knowledge of the problem is improved because we have a larger number of points and we can determine the best linear fit to discriminate between them. However there are regions such as the one where the question mark is where the noise is too high for the model to make a confident prediction. In this case we are referring to aleatoric, or irreducible, uncertainty. This is a really simple toy problem however the same concepts can also be applied to more complex, high dimensional problems.
How are these concepts implemented in everyday machine learning? The short answer is that quite often they are not. The common approach in machine learning is to incorporate every type of uncertainty in the form of probability of model outputs. The problem with these pseudo-probabilities is that they are not statistically robust especially when dealing with non-linear models such as deep neural networks. Having a statistically robust confidence means that, for instance, if a model predicts something with a 90% confidence the prediction should be asymptotically correct 9 out of 10 times. If this does not happen we say that the model is uncalibrated.
So, how do we deal with uncertainty when we have real life machine learning problems? Here are some of the most effectives approaches that we have tried and tested in our Machine Learning projects:
Model calibration which means adjusting the model confidence to be statistically more robust;
Bayesian inference which uses a specific family of statistical machine learning models that are able to incorporate uncertainty in their predictions;
Using external scores and metrics to better estimate the model confidence for a certain prediction.
In the future posts of this series I will explain each of these techniques with practical examples and point you to our relevant code repos. Stay tuned for more on uncertainty quantification!