What happens when you need to train an AI to recycle electronics, but you simply don't have enough data? In our recently completed SYNERWEEE project, a joint effort with the Danish Technological Institute, we set out to solve this exact bottleneck. We're really excited to share some great results with you: by strategically leveraging synthetic data, we saw a nearly 50% improvement in defect detection accuracy for about $10 in API costs.
Every year, millions of tonnes of electronic devices (laptops, phones, screens) are discarded across Europe. A significant share of that waste could be refurbished and given a second life, saving resources and cutting emissions. But there's a stubborn bottleneck standing in the way: robots that inspect and sort WEEE (Waste from Electrical and Electronic Equipment) need to be trained on thousands of images of defects (scratches, dents, cracks) and those images are expensive, time-consuming, and often impossible to collect in the quantities AI models actually need.
That data scarcity problem is precisely what the SYNERWEEE project (Synthetic Data for Enhanced Refurbishment of WEEE) set out to solve. Selected as a beneficiary of the euROBIN 1st Open Call for Collaborative Projects, Clearbox AI partnered with the Danish Technological Institute (DTI), a leading robotics and automation institution, to build a pipeline that generates high-quality annotated synthetic training images on demand. The result is SD4OD: Synthetic Data Generation for Object Detection. And it works.
The Impact at a Glance:
+48.6% mAP50 detection accuracy gain
~$10 Total API cost for the full pipeline run
661 Synthetic images generated automatically
The problem: data that simply doesn't exist.
When DTI first described their WEEE refurbishment challenge to us, the core issue was familiar: too few real images, heavily skewed toward one defect type, with almost no examples of large or rare damage instances. Of their 441 original human-annotated training images, 78.7% of all annotated objects were classified as "tiny" in terms of bounding-box size, while only 1.3% were "large". The dataset was also spatially biased (annotations clustered in the top-right region of frames) and class-imbalanced, dominated almost entirely by "minor scratch" labels.
Training a YOLO object detector on data like that produces a model that is, unsurprisingly, good at spotting small scratches in the top-right corner of an image and not much else. The challenge is that you can't simply go and collect more data: defects are rare by nature, manual annotation is slow and costly, and some defect types may not even appear in a real dataset for months.
The core insight: Rather than collecting more real data, SD4OD statistically analyses what is missing from an existing dataset and synthesises exactly what is needed, targeting the right defect types, at the right sizes, in the right spatial regions.
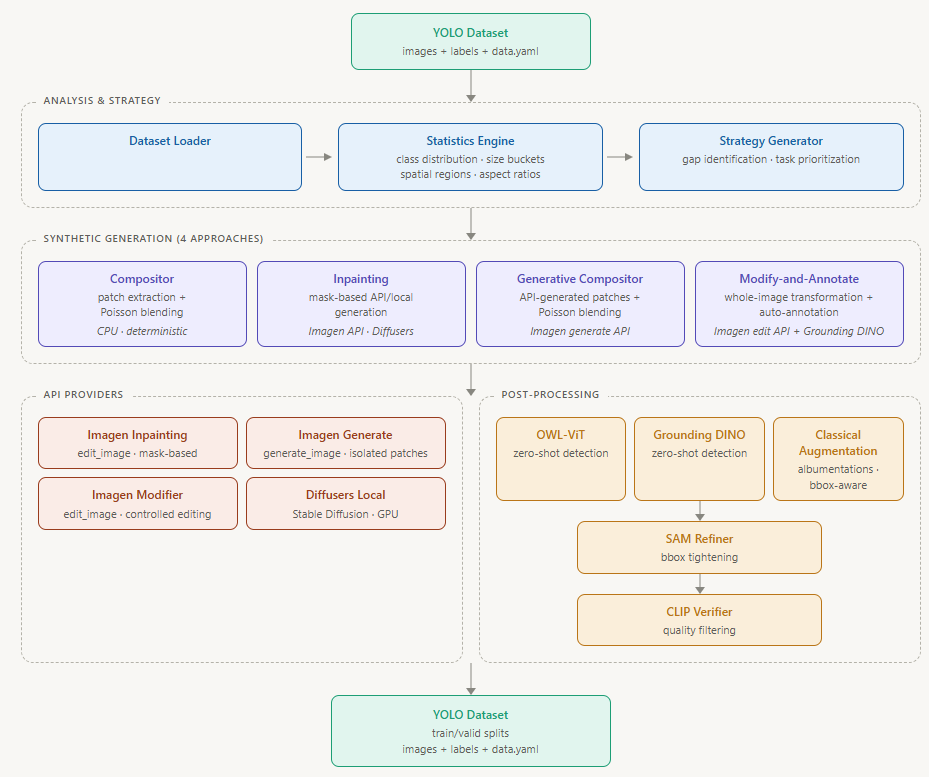
How SD4OD works
The pipeline is a fully modular, end-to-end Python tool. It takes a standard YOLO dataset as input (images, labels, and a config file) and outputs an augmented YOLO dataset ready for model training. Under the hood it runs in three stages.
Stage 1: Analysis and Strategy. A Statistics Engine computes class distributions, size buckets, spatial heatmaps, and aspect ratios across the existing dataset. A Strategy Generator then converts the identified gaps into a prioritised queue of generation tasks, each specifying: target defect class, required object size, spatial region of the frame, and number of images to produce. The pipeline also ensures a configurable target negative ratio (e.g., 15% clean images without defects) to reduce false positives during training.
Stage 2: Synthetic Generation. Four complementary approaches are available, each with its own cost-quality trade-off:
Compositor (offline): Crops real defect patches from existing images using feathered masks, inpaints clean backgrounds, and composites patches onto new backgrounds using Poisson blending. This method runs fully offline on CPU, has zero API costs, and annotations are perfect by construction.
Inpainting: Masks a region and prompts a diffusion model (Google Imagen 3 API or local Stable Diffusion) to fill it with a specified defect. Great for introducing completely new defect varieties into the dataset.
Generative Compositor: Combines the best of both worlds: uses the Imagen Generate API to create a novel isolated defect patch on a neutral grey background, then composites it onto a real image via Poisson blending. This provides access to infinite AI-generated defect variety while guaranteeing perfect bounding box annotations.
Modify-and-Annotate: Applies a whole-image transformation via the Imagen Edit API, letting defects appear naturally integrated within the full visual context. Grounding DINO then automatically detects and annotates the resulting defects, removing the need for manual labelling.
Stage 3: Post-processing and Quality Control. Generated images pass through a CLIP-based quality verifier that crops each bounding box, encodes it, and computes cosine similarity against the text label. Boxes scoring below a configurable threshold (default: 0.25) are discarded automatically. A SAM Refiner tightens bounding box fits, and a Statistical Process Control module using Shewhart X-bar charts flags synthetic annotations that deviate from human ground-truth baselines.
What it cost and what it produced.
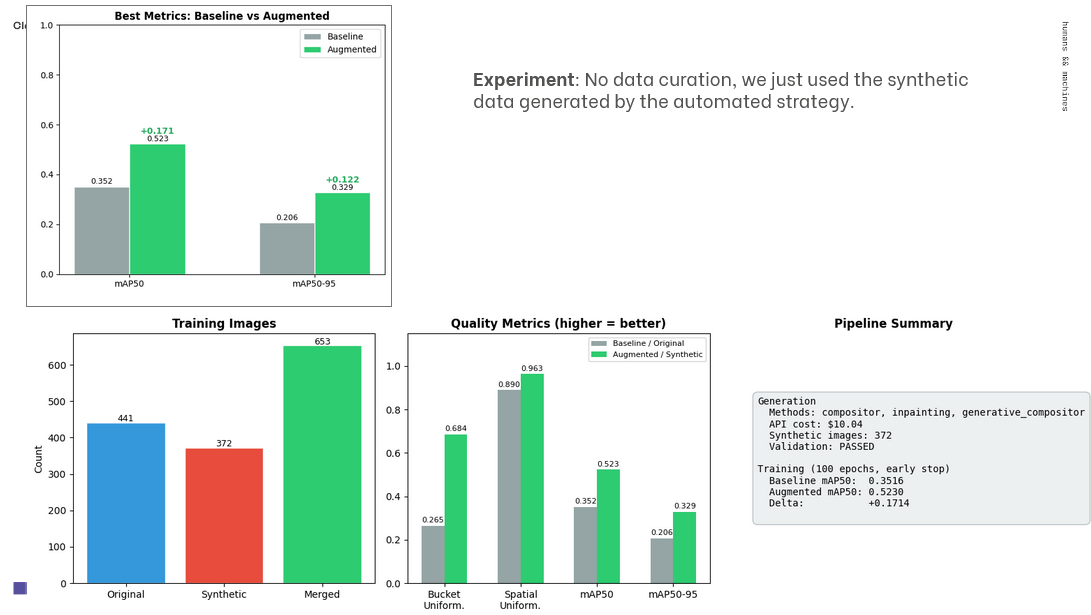
In the demonstration run, the pipeline expanded an initial dataset of 441 images to 1,102 images. The synthesis strategy produced 661 new images across three methods:
Compositor (offline): ~220 images ($0.00)
Inpainting (Imagen API): ~220 images ($4.40)
Generative Compositor (Imagen API): ~220 images ($4.40)
Total: ~661 images ($8.80)
The results: what changed in the data and in the model.
The synthetic pipeline didn't just add images, it actively corrected the extreme class imbalance in the original data. The size distribution went from heavily skewed (78.7% tiny objects) to far more balanced: 20.3% tiny, 21.5% small, 23.8% medium, and 34.4% large. Spatial coverage improved from a top-right concentration bias to a near-uniform distribution across all nine frame regions. Underrepresented classes (Minor Dent, Sticker Marks, Broken, Minor Crack) were boosted to volumes comparable to the dominant Minor Scratch class.
[INSERT FIGURE 8: DATASET ANALYSIS IMAGE HERE]
To evaluate the impact, two YOLOv8n models were trained with identical hyperparameters (100 epochs, early stop). The baseline model was trained exclusively on the 441 original human-annotated images, while the augmented model was trained on a merged dataset of 653 images (441 original plus 372 synthetic). Validation was performed strictly on human-annotated held-out data, and no manual data curation was applied.
Performance Improvements:
0.523: Augmented model mAP50 (compared to 0.352 for the baseline)
+59.2%: mAP50-95 improvement (going from 0.206 to 0.329)
0.963: Spatial uniformity score (improved from 0.890)
Qualitative inspection of detection outputs confirmed the trend. On an image with 4 ground truth boxes, the baseline detected 1 correctly while the augmented model detected 3. On a harder image with 10 ground truth boxes, the baseline found 3 while the augmented model found 4, also correctly identifying a sticker marks region that the baseline missed entirely.
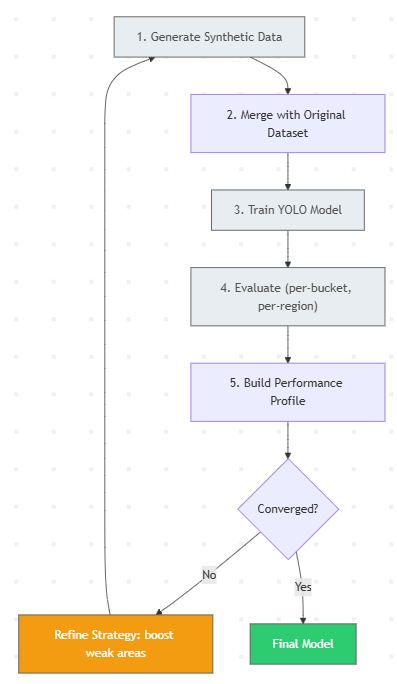
An active learning loop for continuous improvement.
One of the architectural choices we're most proud of is the iterative active learning workflow built into SD4OD to progressively improve model performance. Rather than treating synthetic data generation as a one-shot exercise, the loop operates as follows: generate synthetic data, merge with the original dataset, train a YOLO model, evaluate per size bucket and spatial region, build a performance profile, and refine the strategy to boost identified weak areas. This enables targeted, data-driven augmentation rather than blind volume expansion.
On March 5th 2026, we organized a dedicated symposium open to all to share the SYNERWEEE results with the wider research and practitioner community. We presented the SD4OD pipeline, shared experimental findings, and fostered discussion around synthetic data generation for robotics and AI-powered refurbishment applications.
What's next
The codebase is open-source and available at SD4OD on GitHub. Contributions and collaboration are welcome, whether you want to add a new generation backend, test the pipeline on a different defect domain, or integrate it into your own robotics workflow.
More broadly, the SYNERWEEE/SD4OD project delivers a comprehensive end-to-end framework that moves from blind data collection to targeted synthetic data engineering. When real data is scarce, imbalanced, or simply impossible to collect, synthetic data engineered with precision is the answer.
Acknowledgement: The SYNERWEEE project was funded by the European Union as part of the euROBIN 1st Open Call for Collaborative Projects. Views and opinions expressed are those of the author(s) only and do not necessarily reflect those of the European Union or the European Commission.