
At Clearbox AI we’re building a platform to facilitate the machine learning development pipeline by providing an automated way to analyse models by highlighting strong points and limitations, detecting undesired behavior and assessing generalisability.
Since day one, our focus was on building a model-agnostic tool. We didn’t want to force data scientists to use a specific framework to make their models compatible with our platform. Every developer has their personal “toolbox” and each non-trivial ML project requires specific libraries and custom code. Restricting flexibility and possibilities to our potential future users didn’t sound like a very smart move. So we needed a tool to wrap and save any kind of model to provide it as input to our platform.
We didn't want to reinvent the wheel: each framework (Scikit-Learn, XGBoost, Keras, Pytorch, etc) provides its way to serialise and save a model and there are several open source projects offering such functionality (e.g. Mlfow). What we needed, however, was a simple and clear way to save any data preprocessing functions along with the model in order to have a single production-ready pipeline.
Typically, data are preprocessed before being fed into the model. It is almost always necessary to transform (e.g. scaling, binarising, one-hot encoding) raw data values into a representation that is more suitable for the downstream model. Most kinds of ML models take only numeric data as input, so we must at least encode the non-numeric data, if any.
Preprocessing is usually written and performed separately, before building and training the model. We fit some transformers, transform the whole dataset(s) and train the model on the processed data.
In the simplest case, the original dataset has already been preprocessed, it contains only numerical values (ordinal features or one-hot encoded categorical features) and we can easily train a model on it. Then, we only need to save the model and it will be ready to receive new preprocessed data to make predictions on it.
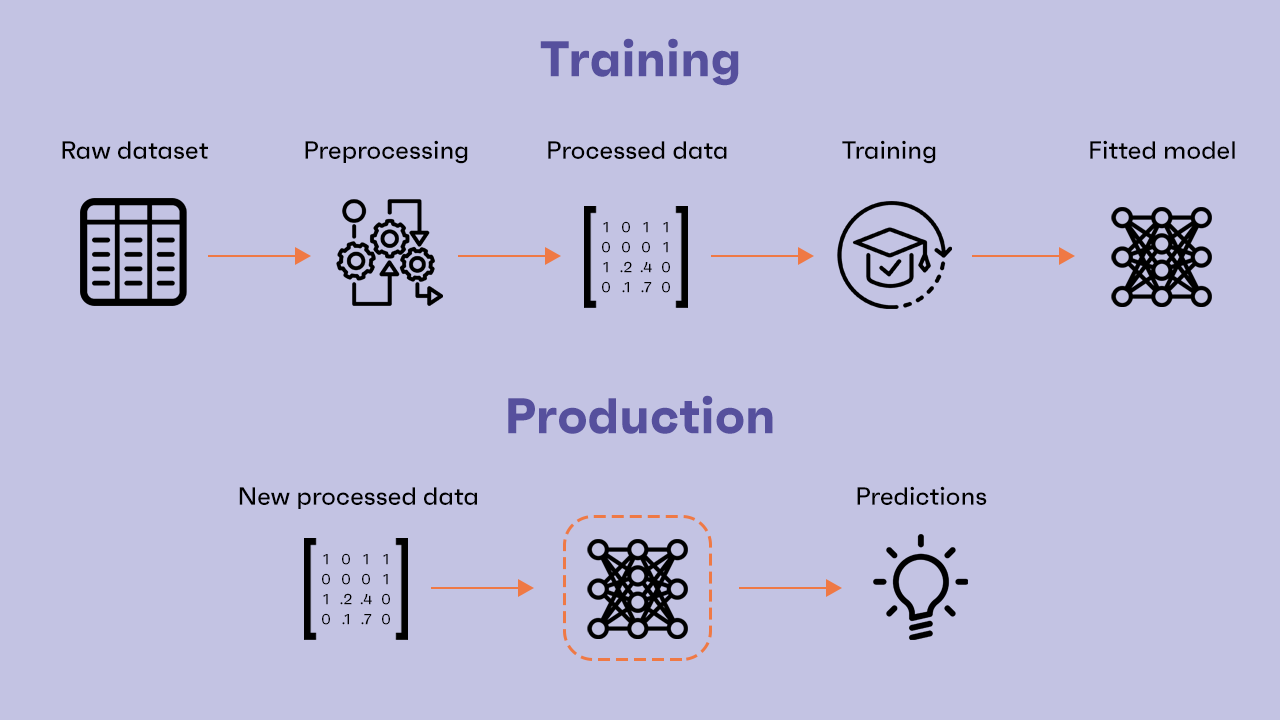
What if the model in production receives raw unprocessed data? This can often happen in non-trivial contexts. For example, data may be provided by final users via a form on a website. We cannot expect the user to provide us with already preprocessed data:

Naturally we need to ship the preprocessing as well. New raw data must be processed in the same way the training dataset was. So we need to wrap and save the preprocessing along with the model in order to have a Preprocessing+Model pipeline ready to take new raw data, preprocess them and make predictions.
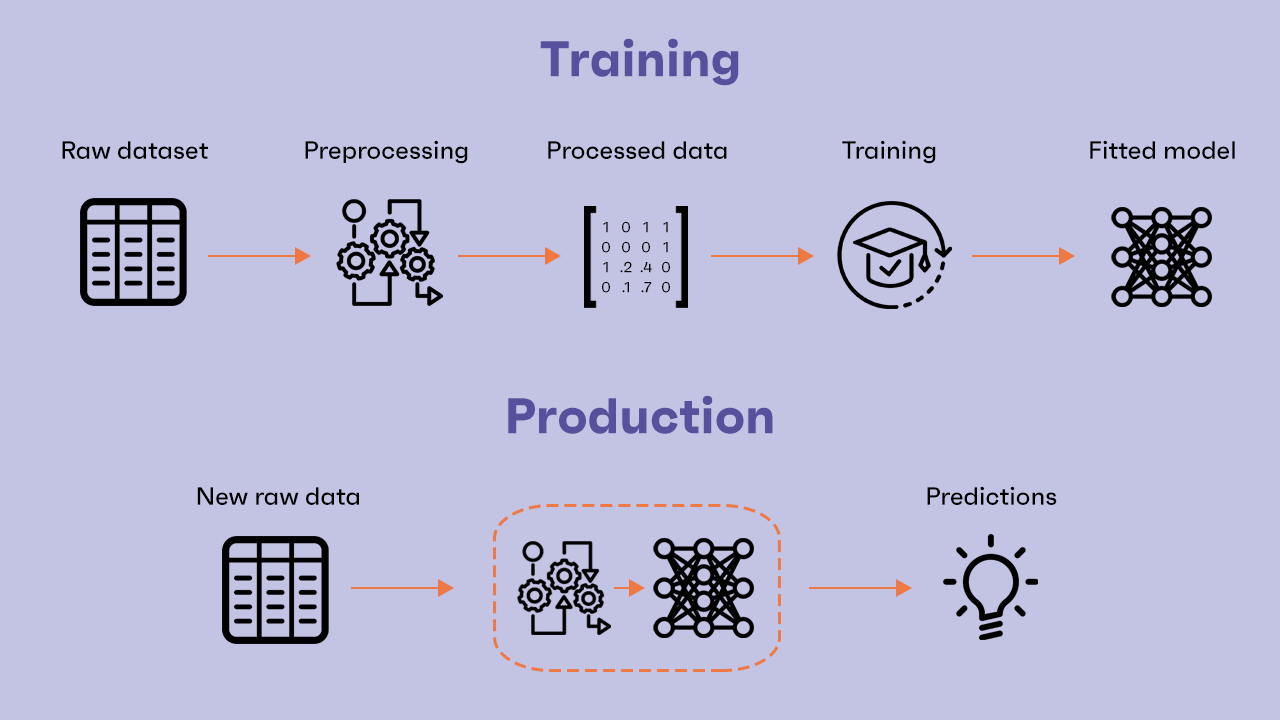
That’s all, right? Not just yet. For a complex task, a single-step preprocessing would not be enough. Raw data initially collected can be very noisy, contain useless columns or splitted into different dataframes/tables sources. A first data processing is usually performed even before considering any kind of model to feed the data into. The entire dataset is cleaned and the following additional processing and the model are built considering only the cleaned data. But what if, again, the data provided to the model in production are unclean? We found that two-step data processing could be a proper way to deal with this situation. We refer to the first additional step by the term Data Preparation.
A legitimate objection could be: Why two different steps? Why not one big preprocessing function? That’s true. Splitting the preprocessing phase into two separate steps is our deliberate choice, but we believe it can offer some advantages.
The data preparation step should be designed and built working only with the original raw dataset, without considering any kind of model your data eventually will be fed in. Any kind of operation is allowed, but often cleaning the raw data includes removing or normalising some columns, replacing values, adding a column based on other column values, etc. After this step, no matter what kind of transformation the data have been through, they should still be readable and understandable by a human user.
The preprocessing step, on the contrary, should be considered closely tied with the downstream ML model and adapted to its particular "needs". Typically processed data by this second step are only numeric and not necessarily understandable by a human.
This approach provides a better division of the logical steps of the pipeline. Furthermore, the output of the two steps could be used for additional purposes, e.g. the analysis of new clean data sent by the final users of the model following a given amount of time.
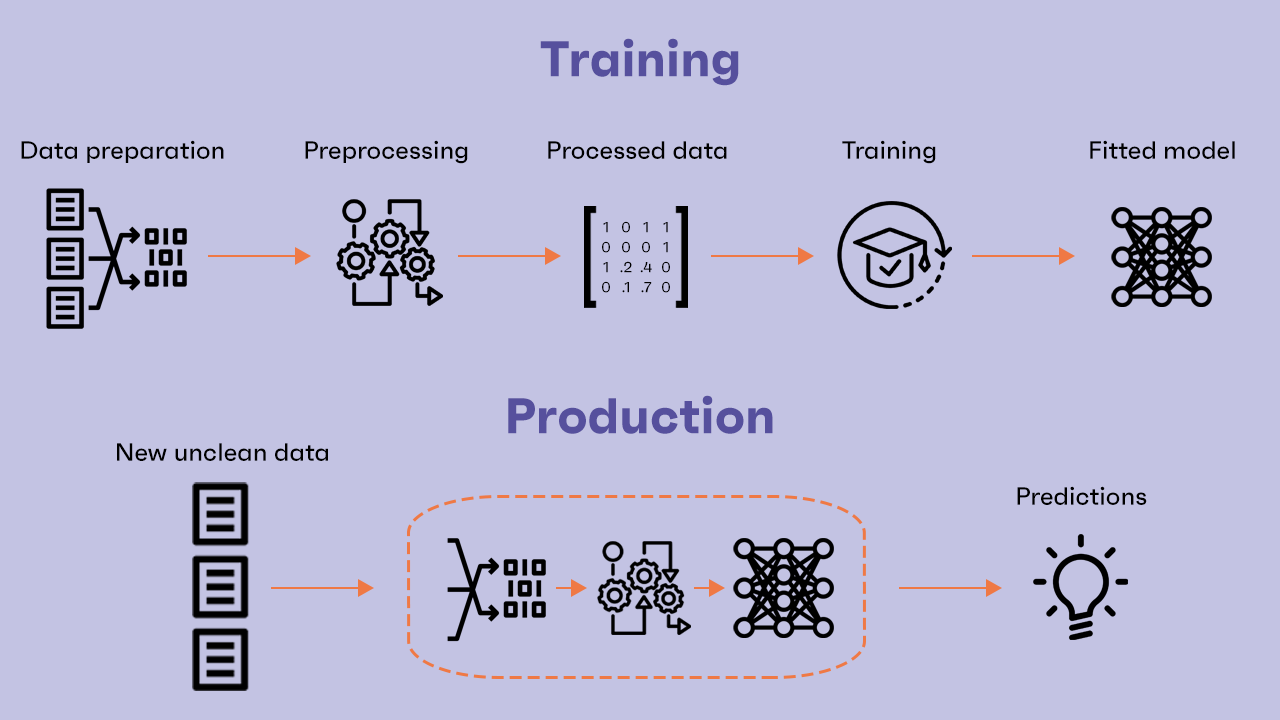
Based on all these considerations, we built a Python library that allows you to wrap and save a ML model together with, optionally, a two-step data preprocessing step In order to have a final pipeline composed by Data Preparation + Preprocessing + Model ready to take new data inputs. It's called Clearbox AI Wrapper. Born as a simple fork from MLFlow, we changed and added several functionalities in the last few months. We think you'll find a lot of interesting features if you give it a go. We are constantly working on improving it, so any feedback is welcome and we’ll be glad to get in touch if you have questions/comments.
